
Introduction
AI models hold tremendous potential to speed up and improve a variety of processes. Marketing is no exception, and AI tools are being rapidly adopted across a wide range of functions including analytics and decision support, whether to support human decision makers or automate processes such as AI-driven programmatic ad serving and targeting. As discussed in our article on AI in marketing analytics, organizations are increasingly embedding machine learning and automation into core measurement and decision workflows.
Marketing has long been a discipline shaped by data, experimentation, and measured uncertainty. Campaign forecasts come with error bands. A/B tests come with confidence levels. Attribution models come with known limitations and assumptions.
In marketing analytics, we are accustomed to asking not just “what happened”, but “how confident are we in that conclusion?” Business decisions involve making choices under uncertainty: understanding the likely outcome of different options, the range of possible outcomes, and how sensitive those outcomes are to assumptions.
Generative AI introduces a meaningful shift in how insights are communicated. Instead of presenting statistical outputs and uncertainty measures, these systems often translate analysis into fluent narrative explanations and recommendations. This can create what might be called a confidence illusion – situations where conclusions sound certain even when the underlying evidence is probabilistic or ambiguous. In this paper, we outline best practices and technical approaches for using generative AI responsibly in business decision making.
I. Decision Making Under Uncertainty
“All data comes from the past, no matter how granular. Yet every business decision concerns the future.”
Business decisions are inherently based on making choices under uncertainty. If I told you that decision A is better than B, the amount of capital you would commit to A would depend on how likely it is that A truly outperforms B. Put differently, whether A outperforms B 55 times out of 100 or 99 times out of 100 matters just as much as the fact that A appears to be the better option.
Marketing decisions are no exception to this. Most marketing analytic tools are built to surface answers under uncertainty, for example:
- Lift estimates from experiments with confidence intervals
- Forecasts with best- and worst-case scenarios
- Marketing Mix Modeling (MMM) and Multi-Touch Attribution (MTA) models with known bias and error rates
- Audience segments scored by probability not certainty
- Propensity models scoring likelihood of purchase or churn
These tools acknowledge the important truth: business decisions are probabilistic. The goal is not perfect accuracy but rather informed risk-taking.
Put another way, analytics help marketers answer two key questions:
- What does the data suggest?
- How strong is that signal?
Good decision making therefore depends not only on identifying the best option, but also on understanding how confident we are in that conclusion.
II. The Confidence Illusion in Generative AI
One of the most subtle risks when integrating generative AI into business decision making is what can be called the confidence illusion (see Callout Box: The Psychology Behind the Confidence Illusion). Humans are naturally inclined to equate clarity of language with strength of evidence. When an answer is expressed fluently, concisely, and without hesitation, we tend to interpret it as a sign that the underlying reasoning must be strong.
Consider the difference between how a statistical report and an AI-generated summary might communicate the same finding:
Traditional analytics output:
“Segment A shows a 4% higher conversion rate than Segment B, but the difference is not statistically significant at the 95% confidence level.”
AI-generated summary:
“Segment A appears to outperform Segment B and should be prioritized.”
Both statements may originate from the same underlying data. Yet the second formulation can easily be interpreted as a stronger recommendation because the uncertainty has been removed from the communication.
Generative AI systems are exceptionally good at producing precisely this kind of communication. Their outputs are grammatically correct, logically structured, and delivered in a confident tone. To a decision maker, the response can feel similar to receiving a recommendation from an experienced analyst or strategist.
However, this fluency is a property of language generation, not a signal of analytical certainty. Unlike traditional analytical tools that explicitly surface uncertainty through confidence intervals, statistical significance levels, or error bands, generative AI systems typically present conclusions in a narrative form without quantifying how reliable those conclusions are.
As a result, weak signals and strong signals can sound identical when translated into natural language.
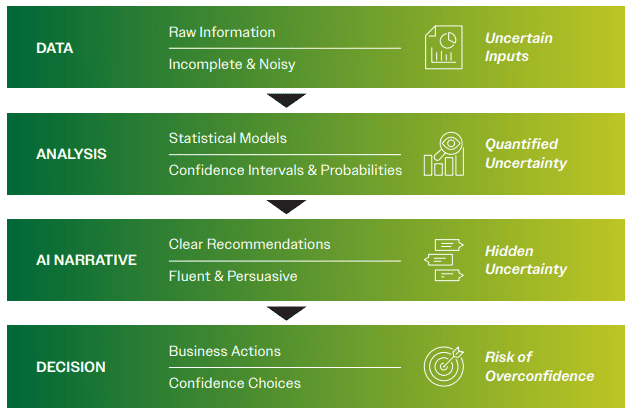
This dynamic can lead to several organizational risks:
- Overinterpretation of weak signals. Small differences in noisy data may be framed as actionable insights.
- False precision in recommendations. AI-generated narratives can give the impression that the optimal decision is clear when the data is actually ambiguous.
- Compression of nuance. Important caveats about sample size, model assumptions, or experimental limitations may disappear when analysis is translated into a concise summary.
- Automation of overconfidence. When AI systems are integrated into dashboards, reporting tools, or automated workflows, these confident summaries can propagate through an organization at scale.
In effect, generative AI can unintentionally convert probabilistic evidence into seemingly deterministic language. The underlying uncertainty has not disappeared; it has simply been hidden from view.
For marketing leaders, recognizing this phenomenon is essential. The persuasive quality of AI-generated insights reflects the system’s ability to produce fluent language, not necessarily the strength of the underlying evidence.
Callout Box: The Psychology Behind The Confidence Illusion
The confidence illusion is amplified by well-documented cognitive biases in human decision making. Research in psychology shows that people often rely on fluency as a proxy for truth. Statements that are easy to read, clearly structured, and confidently expressed are more likely to be perceived as accurate than statements that include caveats or uncertainty.
This phenomenon, sometimes referred to as fluency bias, means that a well-written answer can feel more credible than a statistically rigorous one filled with qualifiers. Generative AI systems naturally produce highly fluent language, which can unintentionally trigger this bias. In addition, AI systems may carry a form of automation authority – people tend to assign greater credibility to outputs generated by complex technological systems, assuming that sophisticated computation implies reliable reasoning. When these two forces combine – high linguistic fluency and perceived technological authority – the result can be recommendations that feel highly convincing even when the underlying evidence is weak or ambiguous.
Recognizing this psychological dynamic helps organizations put appropriate guardrails around how AI-generated insights are interpreted and used in decision making.
III. How Generative AI Models Work
The confidence illusion described above is partly a result of how generative AI systems work. Large Language Models (LLMs), in particular, operate very differently from traditional analytical models.
Rather than estimating relationships between variables and outcomes through statistical inference, LLMs learn patterns from large volumes of language data by predicting the probability of the next token (a word or word fragment) given the preceding context. See Technical Box: LLMs vs. Traditional Statistical Models.

In practice, this means LLMs are optimized to produce fluent and coherent language based on patterns learned from training data rather than to estimate parameters in a statistical model. This makes them exceptionally good at things like:
- Summarizing performance
- Explaining trends
- Drafting insights and recommendations
- Translating data into narratives that executives can consume
However, while LLMs internally operate probabilistically, their outputs do not naturally communicate calibrated uncertainty about real-world claims. When an LLM produces an insight, recommendation or explanation, it typically does so without exposing how confident it is, or how fragile the conclusion may be. In other words, the machine doesn’t explicitly “show its work”. Understanding that shift is critical for marketing leaders.
Example - Segment A or B:
Imagine prompting an AI model: “Which customer segment is more responsive to our new campaign: Segment A or Segment B?”.
The AI responds: “Segment A shows stronger engagement and should be prioritized”. This may be a direct and potentially useful answer. But what is missing is critical context:
- Is the difference statistically meaningful?
- Was the data sparse or noisy?
- Is the conclusion robust or marginal?
In traditional decision science, these contextual questions are central to interpreting results. In a generative AI interface, however, they are often invisible.
Technical box: LLMs vs. Traditional Statistical Models
Traditional statistical models are typically built to estimate parameters of a typical data generating process.
![]()
The goal is interpretable parameters, noise with certain properties and inference and prediction with uncertainty. The model training optimizes likelihoods tied directly to the target variable (y), enabling downstream uncertainty quantification.
Large Language Models (LLMs) optimize a fundamentally different objective:
![]()
Large language models estimate parameters that maximize the probability of predicting the next token given the previous tokens . There is no explicit variable corresponding to “truth”, “lift”, or “effect size”.
Probabilities are also interpreted differently. In a traditional model:
![]()
Where the confidence intervals approximate over parameters or predictions. Model calibration can be evaluated empirically using holdout data with concepts like coverage analysis and Brier score.
In an LLM:
![]()
In other words the probability only refers to the likelihood of the next token and are by construction:
- Local (token level)
- Context dependent
- Not calibrated to any inherent “correctness” or decision outcome
- Are typically collapsed into a single generalized output via decoding like argmax, sampling and temperature
As a result of this what the LLM concludes is a high probability sentence does not necessarily imply a high probability conclusion.
Take the simple example of classifying whether something is a cat or a dog. A traditional classifier model would estimate:
![]()
These probabilities sum to 1, can be calibrated and can be thresholded based on risk tolerance.
When an LLM is asked “is this a cat or a dog?” it may internally assign token probabilities e.g.:
![]()
But in the result only the “chosen” token is surfaced. The decision margin is hidden from the user. Whether it is a high confidence case or a low confidence case, the same textual answer is surfaced.
IV. Why Generative AI Prioritizes Clarity Over Uncertainty Disclosure
While confident answers without showing the work and opaqueness of confidence may seem like a flaw in AI technology, it is actually a design choice. LLMs are optimized for clarity, usefulness and fluency not for statistical disclosure. They are built to provide a coherent answer, because uncertainty or hesitation can feel unhelpful in conversational tools. A way to think of the difference is:
- Traditional analytics behave like a quantitative analyst showing assumptions, caveats, uncertainties and risk
- Generative AI behaves like a strategist or leader delivering a clear answer or recommendation
Both are valuable tools but they are designed to do different things and should not be confused. Problems arise when decision makers interpret clarity of language as strength of evidence. Marketing is full of decisions made under uncertainty:
- Budget allocation
- Channel mix optimization
- Creative or campaign performance evaluation
- Audience targeting and personalization
- Forecasting demand
When generative AI is used to summarize or recommend actions in these areas, unseen uncertainty can lead to overconfidence:
- Small effects may be treated as decisive
- Noisy data may be overinterpreted
- Short term patterns may be mistaken for durable insights
- Automation may outrun experimentation
As generative AI becomes integrated into marketing analytics workflows, this distinction becomes increasingly important. AI tools are increasingly used to summarize campaign performance, generate automated reporting insights, interpret dashboards, or assist in evaluating audience segments and media performance. Many organizations are already exploring these capabilities as part of broader efforts to streamline marketing data management using generative AI.
In these contexts, AI systems often act as a translation layer between analytical outputs and business decision makers, converting model results, experiment outcomes, and performance metrics into concise narrative summaries. When this happens without explicit measures of uncertainty, the confidence illusion can easily arise in day-to-day marketing decision making.
V. Best Practices for Using Generative AI For Decision Making
Just as executives learn to ask analysts about assumptions and confidence levels, they should develop similar habits when interacting with AI-generated recommendations.
Leading marketing organizations are integrating generative AI into decision processes while maintaining analytical discipline. Managerial best practices include:
- Leverage generative AI models to explain, not decide. Let LLMs translate analysis into insights, not replace the analysis itself.
- Anchor AI insights to measurable outputs. Tie recommendations back to experiments, lift estimates, and model outputs with known error characteristics.
- Look for consistency, not just plausibility. If the same question yields different recommendations across runs, that is a signal of uncertainty.
- Make uncertainty a required discussion point. Ask “What assumptions does this depend on?” or “How sensitive is this conclusion to the data?”
- Match the tool to the risk. The higher the business impact or capital at stake, the more important explicit uncertainty becomes.
The most effective organizations treat generative AI as a tool that translates analysis into narratives, while ensuring that the analytical foundation remains visible.
VI. Technical Methods to Recover Uncertainty in AI Workflows
At a technical level, practitioners can apply a range of methods to recover or quantify uncertainty in AI-assisted decision frameworks:
Bayesian Inference
Bayesian approaches treat uncertainty as a first-class input rather than an afterthought. Instead of asking “what does the data say?”, a Bayesian framework asks: given what we already know, how should new data update our beliefs?
In practice, this means incorporating prior knowledge such as historical conversion rates or typical campaign lift and updating estimates as new evidence arrives. Applied alongside LLM outputs, Bayesian methods can translate recommendations like “prioritize Segment A” into probabilistic statements about the likelihood that one option truly outperforms another.
Monte Carlo Simulation
Monte Carlo simulation stress-tests conclusions by running thousands of scenarios with slightly different assumptions and observing the distribution of outcomes.
In marketing contexts such as budget allocation, demand forecasting, or campaign ROI modeling, this approach reveals how sensitive a recommendation is to the assumptions behind it. If a recommended strategy performs well across most simulated scenarios, confidence increases; if outcomes vary widely, the signal may be fragile.
Prediction Intervals
Prediction intervals quantify the range within which a future outcome is likely to fall, rather than providing only a single point estimate.
For example, a forecast might state that “next quarter’s revenue is expected to be $4.2M, with a 90 percent prediction interval between $3.8M and $4.7M.” LLM-based systems can be adapted to produce analogous outputs by prompting probabilistic responses or by using token probability outputs as a proxy for model confidence. While this requires additional implementation, it provides a way to surface uncertainty in AI-generated narratives in a form that business users can interpret.
Ensemble Models
Ensemble methods combine the outputs of multiple models, or multiple runs of the same model with different configurations, rather than relying on a single output.
The degree of agreement across the ensemble is itself informative: when models consistently point in the same direction, confidence increases; when they diverge, that divergence signals uncertainty. In an LLM context, this can be implemented by querying the model multiple times with varied prompts or parameters and comparing the responses.
Calibration Techniques
Calibration measures how well a model’s expressed confidence aligns with its actual accuracy. A well-calibrated model that says it is “90% confident” should be correct roughly 90% of the time.
LLMs, however, often produce confident-sounding language regardless of the strength of the underlying evidence. Several techniques can help correct this tendency. Post-hoc scaling with validation data compares past AI-generated recommendations with observed outcomes and adjusts confidence estimates accordingly. Temperature scaling modifies the model’s output distribution to produce more reliable probability estimates, while Platt scaling and label smoothing apply statistical correction layers to improve calibration.
For marketing decisions involving significant budget or strategic risk, AI-generated outputs should ideally be validated against historical performance data and calibrated before being used as a basis for action.
Conclusion
Generative AI is a genuine leap forward for marketing analytics. It can compress hours of analysis into minutes, translate complex data into executive-ready narratives, and surface patterns that might otherwise go unnoticed. These are real and meaningful advantages that marketing organizations should be actively exploiting.
But speed and fluency are not the same as rigor. The same quality that makes generative AI so useful – its ability to produce clear, confident, well-structured language – is also what makes it potentially dangerous when used uncritically for high-stakes decisions. An AI system that says "prioritize Segment A" sounds identical whether that conclusion rests on a statistically robust experiment or on a handful of noisy data points. The uncertainty has not disappeared. It has simply been edited out of the final draft.
Marketing has always been a discipline that operates under uncertainty. The best marketing organizations don't pretend otherwise, they quantify it, stress-test it, and build it into their decision making. The arrival of generative AI does not change that imperative. It raises the stakes for it.
The leaders who will get the most out of these tools are not those who treat AI-generated recommendations as answers, but those who treat them as starting points. These insights should still be interrogated, grounded in experimental evidence, and pressure-tested before they drive meaningful resource allocation.
Clarity of language is a communication virtue. It is not a substitute for analytical certainty. As generative AI becomes more deeply embedded in marketing workflows, keeping that distinction visible, and acting on it, is one of the most important responsibilities marketing leaders have.
Applying These Ideas In Practice
If your organization is exploring how generative AI can support marketing decision-making, Marketscience helps companies design measurement frameworks that combine advanced analytics with practical decision support.
Contact us to get started applying AI to enhance your marketing analytics workflows.

References
Alter, A. L., & Oppenheimer, D. M. (2009). Uniting the tribes of fluency to form a metacognitive nation. Personality and Social Psychology Review, 13(3), 219–235.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Proceedings of the ACM Conference on Fairness, Accountability, and Transparency.
Fazio, L. K., Brashier, N. M., Payne, B. K., & Marsh, E. J. (2015). Knowledge does not protect against illusory truth. Journal of Experimental Psychology: General, 144(5), 993–1002.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2023).
Survey of Hallucination in Natural Language Generation. ACM Computing Surveys.
Lin, S., Hilton, J., & Evans, O. (2022). TruthfulQA: Measuring How Models Mimic Human Falsehoods. ACL Conference on Empirical Methods in Natural Language Processing.
Logg, J. M., Minson, J. A., & Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes, 151, 90–103.
Marketscience. (2024). Harnessing the power of AI in marketing analytics. Marketscience.
https://market.science/harnessing-the-power-of-ai-in-marketing-analytics/
Marketscience. (2024). Streamlining marketing data management with generative AI. Marketscience.
https://market.science/streamlining-marketing-data-management-with-generative-ai/
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253.
Reber, R., Schwarz, N., & Winkielman, P. (2004). Processing fluency and aesthetic pleasure: Is beauty in the perceiver’s processing experience? Personality and Social Psychology Review, 8(4), 364–382.
Xiong, M., et al. (2023). Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Calibration in Large Language Models. arXiv:2306.13063.