
Abstract
As marketing data grows more complex and fragmented across CRMs, social platforms, web analytics tools, and third-party sources, transforming that data into actionable insight has become one of marketers’ biggest operational hurdles. Generative AI, especially large language models (LLMs), offers a new way forward: automating repetitive tasks like cleaning, structuring, and integrating data with impressive speed and scale. This article explores where LLMs add real value in marketing data workflows, where they still fall short, and how three leading models – ChatGPT, Claude, and DeepSeek – perform on practical daily tasks faced by marketers, guiding organizations in selecting and applying the right tools to drive measurable value.
I. The Benefits of Incorporating AI/LLMs into Marketing Data Processing Workflows
Generative AI models, capable of translating natural language instructions into structured code, are increasingly being used to automate and streamline marketing data workflows. Their value lies in their ability to handle repetitive, labor-intensive tasks with speed and accuracy, making complex data more accessible and usable.
One of the most immediate advantages of AI lies in automated data collection and categorization. These systems can efficiently scrape, extract, and consolidate information from a wide array of sources. They not only reduce manual labor and the risk of human error but also maintain a continuous flow of data. Furthermore, generative AI can classify and tag unstructured inputs – like social media posts and customer feedback – based on thematic and keyword analysis, making raw content easier to analyze.

Another essential use case is data cleaning and de-duplication. AI excels in recognizing inconsistencies across datasets, identifying repeated entries, correcting formatting issues, and standardizing data collected from multiple platforms. More advanced models can even convert free-text fields into structured formats and translate inputs across languages, a vital feature for global brands. Some AI models are capable of detecting anomalies, such as unexplained spikes in ad engagement or duplicate user identities, helping marketers flag potential issues in real time.
Once data is clean, it needs to be transformed and harmonized for effective use. Here, AI and LLMs offer intelligent mapping capabilities that unify disparate data structures into consistent formats. They can generate SQL queries, dynamically build field mappings, recognize naming variations, and even identify missing data elements. This transformation process ensures that data is properly formatted for integration into centralized databases or dashboards.
Lastly, AI assists in the creation of Extract, Transform, Load (ETL) pipelines, enabling marketing and analytics teams to automate much of their backend data processing. Whether it's writing Python scripts to clean messy input fields or assembling full workflows that execute end-to-end data harmonization, LLMs reduce the reliance on manual coding and speed up deployment.
II. Limitations of AI in Marketing Data Processing
While AI brings substantial benefits, it is not without its limitations. One major constraint is the requirement for high specificity in prompts. For complex tasks, LLMs often need very detailed and well-structured instructions to avoid misinterpretation. This can slow down workflows and increase the need for human oversight.
Another challenge is the models' limited inferential processing. When instructions are ambiguous, some models fail to ask clarifying questions or may make incorrect assumptions, leading to flawed outputs. Additionally, there are significant concerns around data privacy and security. Sensitive marketing data must be handled with care, and not all AI platforms meet the compliance standards required for regulated industries.

III. Comparative Analysis: Leading LLMs for Data Processing and Harmonization
 As part of this exploration, we have evaluated the performance of three leading large language models in executing marketing data processing tasks:
As part of this exploration, we have evaluated the performance of three leading large language models in executing marketing data processing tasks:
A. Evaluation Criteria
To assess the models, we examined several core capabilities:
- Accuracy of Language Interpretation and Natural Language Processing
We evaluated how effectively each model understood transformation instructions. This included its ability to interpret complex requests, handle ambiguity, and ask clarifying questions when needed. We also assessed whether its assumptions were logical when inputs were vague.
- Performance and Output Accuracy
This criterion focused on how well the models executed data processing tasks. We assessed their ability to carry out complete transformations, extract insights correctly, and generate high-quality, reusable code that adhered to best practices.
- Explainability and Transparency
A good model doesn't just produce the right output, it explains how it got there. We examined whether each model provided clear rationales for its decisions and offered actionable recommendations. The quality of in-line code documentation and the clarity of step-by-step explanations were also evaluated.
- Consistency
We tested how reliably each model responded to identical prompts and whether its transformation logic remained stable across different but similar queries.
B. Testing Procedures
Each model was given the same set of data-related tasks, including:
- Data Processing
- Data Recognition
- Time Series Analysis
- Code Generation
These tests were designed to simulate real-world marketing data scenarios requiring flexible language comprehension alongside technical precision.
C. Results and Findings
Task 1: Data Processing
This task involved cleaning, standardizing, and aggregating marketing performance data with inconsistent formats and ambiguous entries – a common challenge for marketers working with disparate data sources.
- Claude demonstrated exceptional problem-identification capabilities, flagging ambiguities (like whether “Na” meant “North America” or “not applicable”) and generating clean, well-documented JavaScript code with built-in error handling and visual summaries.
- ChatGPT completed the task accurately but made assumptions without flagging potential data issues (e.g. didn’t question the unclear “Na” connotation, assuming by default that it referred to “North America”). It produced Python code which was functional and included some basic documentation and error handling.
- DeepSeek failed to deliver a working solution, even after several debugging attempts. It showed instability in retaining prior fixes – a major concern for workflows requiring precision.
Task 2: Data Recognition
This tested the models’ ability to recognize relationships between marketing data points across multiple Excel tables and generate meaningful insights, similar to analyzing campaign performance spreadsheets from various platforms.
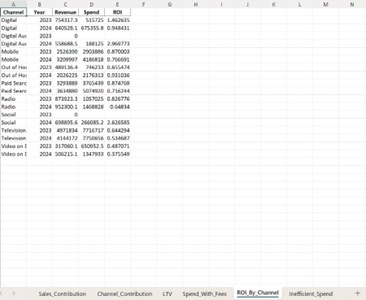
- Claude excelled, providing the richest output: clear data mapping, strategic insights, and flexible formats (Markdown, PDF). It also offered reusable scripts for similar tasks. See sample output below:

- ChatGPT took a structured approach with intuitive labeling (using ✅, ⚠️ symbols) and helpful clarifications e.g. which version of the marketing spend to use before running ROI calculations. It returned practical deliverables like .xlsx and .pptx files. See sample output below:
- DeepSeek produced acceptable results but with less organization, minimal commentary, and inconsistencies in how it presented insights.

Task 3: Time Series Analysis
This focused on processing time series marketing data including trend analysis, outlier detection, and interpolation – essential skills for marketers analyzing campaign performance over time.
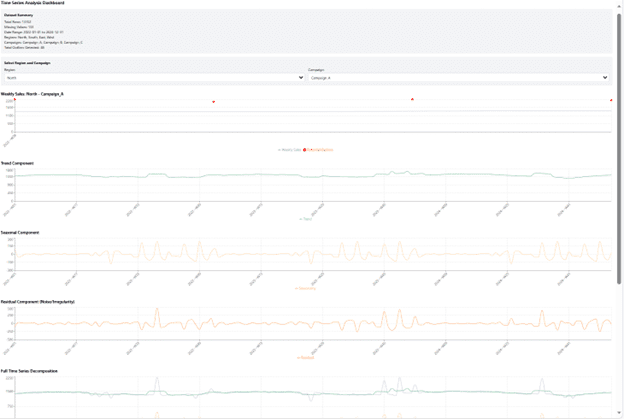
- Claude stood out again with interactive, filterable dashboards that allowed exploration across all region/campaign combinations. It provided detailed commentary on inflection points, seasonal patterns, and business implications, as shown in the output below:

- ChatGPT completed all technical requirements but only delivered a finalized database with static visualizations for a single region/campaign combination. Its analysis of trends and strategic recommendations were less deep and specific. See sample output below and to the side:
 ChatGPT completed all technical requirements but only delivered a finalized database with static visualizations for a single region/campaign combination. Its analysis of trends and strategic recommendations were less deep and specific. See sample output below and to the side:
ChatGPT completed all technical requirements but only delivered a finalized database with static visualizations for a single region/campaign combination. Its analysis of trends and strategic recommendations were less deep and specific. See sample output below and to the side: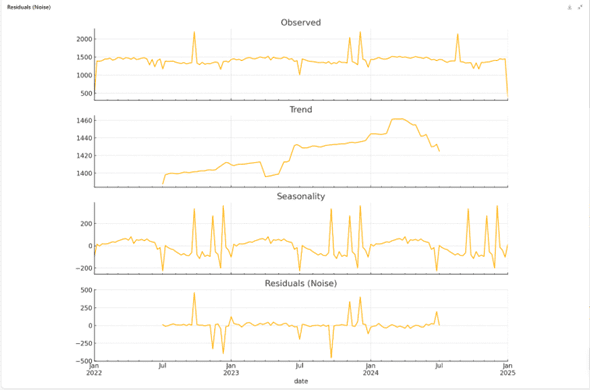
- DeepSeek showed technical competence in basic data processing but lacked interpretive depth, offering generic takeaways that didn’t tie back to the dataset, as seen below. This suggests weaknesses in translating technical output into business recommendations.

Task 4: Code Generation
This final task tested the models' ability to process and aggregate multiple marketing data files with various segmentations, a common requirement for building ETL pipelines for marketing analytics.
- DeepSeek was excluded from this evaluation round due to its considerable challenges with the initial three tasks.
- ChatGPT created functional code but required several iterations and included several limitations for future use such as hardcoded paths that would require manual updates for new data sources, limited error recovery and minimal fallback mechanisms for file reading issues. See sample output below:
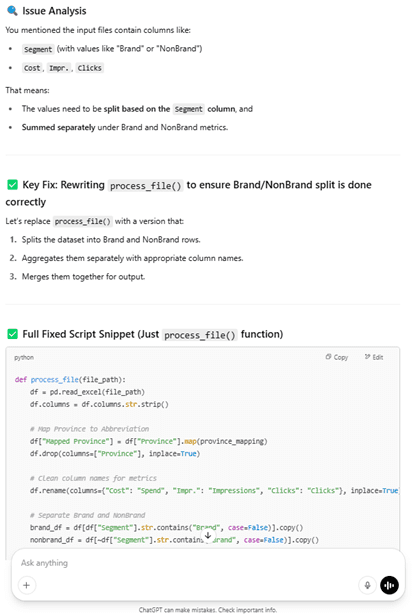
- Claude approached the task methodically, asking for clarification before coding. It delivered clean, modular Python code with parameterized functions that could be easily modified for different data sources, support for multiple file types, and robust error handling including detailed logging for troubleshooting. Its final solution demonstrated significant advantages for future reusability. See sample output below:

LLM Performance Comparison
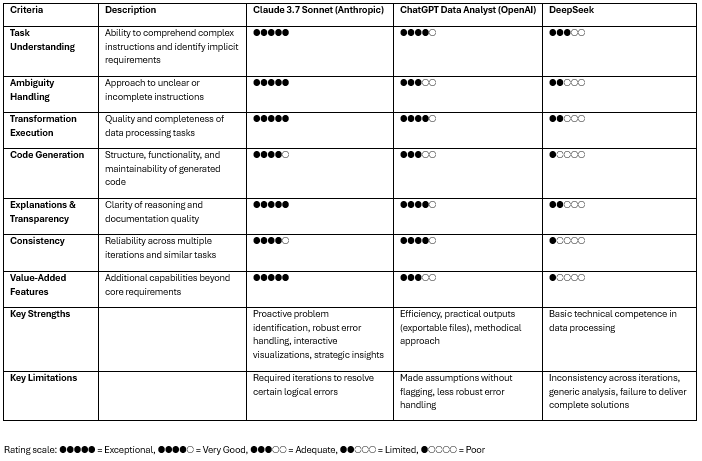
Common Patterns and Implications
Across all tasks, we observed several consistent patterns that highlight both the potential and limitations of using LLMs for marketing data processing:
- All models showed some degree of limitation in complex logical reasoning, requiring multiple iterations to resolve certain issues. Even the strongest performer, Claude, needed iterations to correct logical errors in the code generation task, highlighting that human oversight remains essential in these workflows.
- Problem identification varies significantly between models, with Claude consistently demonstrating the strongest ability to identify potential data issues without making assumptions – a critical capability when working with the often messy and inconsistent data sets marketers encounter.
- Documentation quality directly correlates with code robustness. Models that provided more thorough explanations and documentation generally produced more maintainable and error-resistant solutions.
IV. How Marketscience Can Help: Fast, Focused Data Process Diagnostics
After exploring the strengths and limitations of generative AI for marketing data processing, one thing is clear: many businesses are still navigating in the dark. They know their data is fragmented and underutilized, but they’re unclear on where to begin, which tools to trust, and how to apply them effectively.
Marketscience offers a short (2-3 week) diagnostic designed to evaluate how your organization collects, cleans, and integrates marketing data. We assess key areas like:
- Data collection methods (manual vs. automated)
- Cleaning and de-duplication processes
- Harmonization across platforms
- Data quality management
- Current and potential uses of AI or LLMs
Our team provides a tailored report highlighting gaps, inefficiencies, and opportunities for automation. It’s a quick, low-commitment way to benchmark your data processes and uncover smarter ways to work.
If you’re looking to reduce manual overhead and unlock more value from your marketing data, we’d be happy to explore whether our diagnostic is a good fit. Contact us today!
